How RAG works
In a lot of ways, the biggest opportunity in LLMs is learning how to extend their knowledge through reliable data sources that contain the answers to the user's questions. Feeding this data into the LLM correctly makes the LLM smarter and more reliable. RAG is how you do that. This post will describe how it works from first principles. If you're interested in building a RAG pipeline right now, I'd advise you to go here.
RAG (Retrieval Augmented Generation) is a very simple concept: It's a data pipeline for LLM applications that feeds relevant data into the prompt of an LLM so that it can produce a better response for the user.
This method works because the nature of LLMs is that they are better at imitating rather than innovating. This means that if you want LLMs to return certain information (such as private, up-to-date, or more accurate data), then putting that data into the prompt as context for the model allows it to return that information in an easy-to-read way, hence the name "Retrieval Augmented Generation":
An LLM takes in a Query, Retrieves data from a data source, Augments this raw data, and Generates an answer for the user.
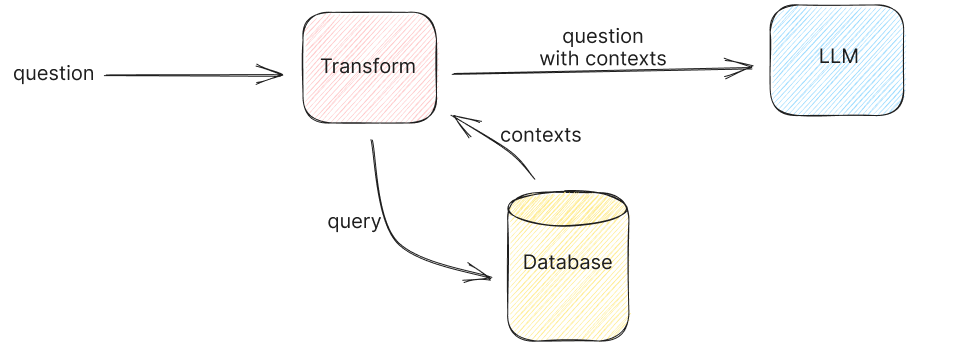
There are a few main components to every RAG pipeline and they are:
- The Data Source
- The Retrieval System
- The LLM
- The Application Layer
Data Sources:
Your source of data will come from either data you gather and store yourself, or from an API to a data source. Both have their pros and cons.
For getting and storing data yourself, it gives you the flexibility to gather whatever you want, format however you want, retrieve however you'd like, and scale at will. It's typically cheaper, depending on how much data you're looking to get, and it can give you a competitive advantage by having data which others don't.
However, some data is only accessible through an API. An example of this is the Reddit API or a Web Search API such as Tavily. These APIs offer very valuable data for your application with an easy way to integrate the API.
It's become clear that the data provided to the LLM is where the value is added for a RAG app. Here are some companies who focus on RAG and what data they use:
-
Perplexity: Web Crawlers
-
SourceGraph: Github Repositories
-
Mendable: Documentation Sites
-
Amazon Q: AWS Documentation
-
SEC Insights: Quarterly Earnings for FAANG companies (by LlamaIndex)
-
Honorable Mentions:
Although there will be many more startups that soon pop up with a proprietary data advantage, the trend is becoming clear: attach your LLM with useful data to answer questions with a higher level of confidence (and provide sources)!
Retrieval Methods
Now that you have all of this useful data, you have to organize it in a way that it can be easily searched so that the correct documents are returned to the LLM and in the correct format. This starts to become very use-case specific, although there are some general best practices that are emerging. From our experience, here are some tips for Retrieval on Unstructured Data:
-
Stay away from using Naive RAG.
- This typically means using only an embedding model with a vector database to embed large chunks of text in the same dimension size as embedding the query which is used to search on that text.
-
Try out Hybrid Search with SPLADE or BM42 for searching on your unstructured data.
- In short, Hybrid Search combines keyword and vector search for some really good search results.
- Some drawbacks are that it requires a few extra steps in the data embedding and upserting process.
-
Knowledge Graphs are growing in popularity.
- Cons: Very hard to set up and query. Not the ideal method for every use-case.
- Pros: Allows for a much better understanding of the entire data corpus and can provide much higher quality results.
We recommend Hybrid Search to everyone. For the Vector store to do this with, we recommend Pinecone (closed-source) and QDRANT (open-source) and to use SPLADE and BM42 models with each vector database respectively.
If you're interested in doing RAG with structured data, we recommend reading this.
Other things to consider include:
LLMs for RAG
When deciding which LLM to use, you must take these factors into consideration:
-
The Model's Context Length: Your chunks of text sent to the model must be less than the context length.
-
The Model's Knowledge Cutoff: This is especially important for when you are having a model do queries to your data source. Models with more recent knowledge cutoffs will know terminology that may not have existed 2 years ago when some other model's knowledge cutoff is.
-
Speed: To decrease latency in your app, you want a fast model to take care of steps in your RAG pipeline that require an LLM, but not a lot of knowledge. Our favorite right now is Haiku.
-
Function Calling: This is getting into the weeds a bit, but when building a RAG app, you will likely need an LLM to call functions (tools). It's important to know that Anthropic and OpenAI models approach function calling differently and that Anthropic models are much better at using XML tags than other models.
To our knowledge, there is only one LLM trained specifically for RAG: Cohere's Command-R+.
However, our current favorite LLM for RAG apps based on Price, Performance, and Speed is of course Claude Sonnet 3.5.
The Application Layer
We have yet to see many good RAG App UIs since AI engineers are usually bad at frontend. However, we believe that the application will set apart many RAG apps in the near future. Here is our wishlist for your RAG app UI:
- Show the intermediate steps.
- A good example of this is https://www.secinsights.ai/
- Let the user edit search queries and past steps made by the LLM.
- This hasn't been implemented in any app we've seen, but it makes a lot of sense. If you use ChatGPT or Anthropic's workbench, then you likely change past prompts or even change the AI response to what you'd ideally like. Making this available to users for apps that have multiple steps will give the users a lot of freedom and produce higher results.
- A way to see this in action is through Langchain's Langgraph Time-Travel example.
- Add a 'Human-in-the-Loop' function for agents that do an impactful task.
- As AI apps begin to have more permissions to take actions, it's important to add a human-in-the-loop to make sure the AI doesn't mess anything up. A good use-case for this is an AI app that can edit a GitHub repository.
For more information on building a RAG app, here are some great YouTubers we like to watch: